SEO
更新日2025年08月26日
公開日2023年1月17日
robots.txtの書き方とは?確認方法やSEO意識した使用ケース、記述例も紹介
ページ数の多い大規模サイトは、ときに不要なページへのクロールを制御する必要があります。
その際に利用するのが「robots.txt」です。
Webサイト全体や各ページ、画像や動画といったファイルなど。
robots.txtファイルを作ることで、それぞれの場所へのクロールを禁止したり、許可したりといった指示をクローラーに伝えます。
robots.txtは、テクニカルSEOの施策の一つ。
つまり、どちらかといえばWebサイトの構造に対する知識があったほうが、対応しやすい内容といえるでしょう。
ただ、専門知識がなくてもrobots.txtの設定は可能です。
私もかつてWeb知識がない状態で、robots.txtに挑んだことがあります。
最初は言っている意味がまったくわかりませんでしたが、難しい言い方をしているだけで実際はそれほど難しくないことに気づきました。
Nobilistaブログではそんな当時のことを思い出しつつ、Webに対する専門知識が無い方と同じ目線で、わかりやすい解説をしたいと思います。
大手企業も続々導入中!
多機能型 検索順位チェックツール「Nobilista(ノビリスタ)」
Nobilistaは、365日完全自動で大量の検索キーワードの順位を計測するSEOツールです。
※7日間の無料トライアル実施中
テクニカルSEOとは?コンテンツSEOとの違いや施策の種類、メリット・デメリットを紹介
robots.txtとは

「robots.txt(ロボットテキスト、ロボッツテキスト)」とは、クロールに関する指示を書いたクローラーのためのファイルです。
robots.txtファイルを作り、Webサイトにアップロードすることで、クロールを禁止したり、許可をしたりとクローラーの制御が行えます。
ファイルに記述する内容によっては、サイト全体だけでなく特定のページ、画像や動画といった特定のファイルに対してのみ、クロールの制御を行うことも可能。
ほかにも、検索結果に表示している画像や動画など、特定のメディアファイルを非表示にする際にも利用されます。
クローラーとは?意味や仕組み、巡回を促す対策、拒否する方法をわかりやすく解説
robots.txtが制御するクロールとは
クローラーとは、Webサイトの内容を読み取り、どのようなサイトかを理解するためのプログラムです。
Google botやスパイダー、ボットとも呼ばれます。
つまり、検索結果にWebサイトを表示したい場合、クローラーに来てもらい、Webサイトを認識してもらわなければいけません。
ちなみに、クローラーにWebサイトを認識してもらうことを「クロールする」といいます。
その後は以下のような流れを経て、検索結果に表示されます。
- クローラーが巡回し、Webサイトの中身を把握する(=クロール)
- 「インデックス」される
- ユーザーに検索される
- アルゴリズムにより、適切なWebサイトをインデックスから選出
- 検索結果に適切と判断したページ順に表示
※インデックスとは、WebサイトをGoogleが決めた項目に沿って整理して記録すること。
ちなみに、クローラーは何度もWebサイトを回遊しに来ます。
なぜなら、最新のWebサイトをインデックスしたいからです。
別の見方をすれば、最新のWebページをユーザーに見せるために、頻繁にWebサイトを回遊してくれているともいえるでしょう。
クローラーは、クロールをする前にrobots.txtファイルがないか、常に確認してくれます。
robots.txtファイルがあれば、クローラーは指示に沿って、該当のページやファイルをクロールしません。
そのかわり、クロールがされなければ、現時点でインデックスされているページを表示し続けます。
インデックスとは?SEOとの関係や確認方法、登録方法を解説
robots.txtの「Disallow」と「noindex」の違い
「robots.txt」と「noindex」は似ているようで異なるものです。
noindexはその名の通り、インデックスを禁止するためのもの。
両者の違いは「クロールするかしないか」。
そして「インデックスは残るかどうか(=検索結果に表示し続けるかどうか)」といえるでしょう。
クローラーがnoindexを見つけた場合。
現時点でインデックスされている記録も削除します。
同時に、検索結果にも表示されなくなります。
一方robots.txtの場合、現時点でのインデックスは残ります。
つまり、検索結果にも表示され続けるということです。
また、noindexはクロールすることが大前提といえます。
なぜなら、クローラーが回遊してはじめて、noindexがあるかどうか認識できるからです。
使い分けとしては、インデックスからページを削除したい(検索結果に表示しないようにしたい)場合はnoindex。
クロール自体をしてほしくない場合は、robots.txtと考えましょう。
| robots.txt (ファイルをアップロード) | noindex (HTMLにタグを記載する) |
| 主な用途は、クロールの制限(節約) | 主な用途は、検索結果に表示したくないページやインデックスされているページの削除 |
| クロールしない | クロールする |
| インデックスは残る (検索結果に表示され続ける) | インデックスは残らない (削除され、検索結果にも表示されない) |
ちなみに、robots.txtとnoindexの両者を、併用しないよう注意してください。
すでにお話したとおり、noindexはクロールされてはじめて適用されます。
つまり、robots.txtでクローラーをはじいていたら、noindexが適切に動作しません。
noindexタグとは?設定方法やSEOへの影響、実装ページの確認方法を解説
記述に関係するWebサイトの構造
Webサイトの構造やURLの仕組みについて知っておくと、robots.txtの記述についてより理解を深めることができます。
まずは簡単に、Webサイトがどのような構造をしているのか見てみましょう。
Webサイトは、一言でいうとフォルダのような仕組みをしています。
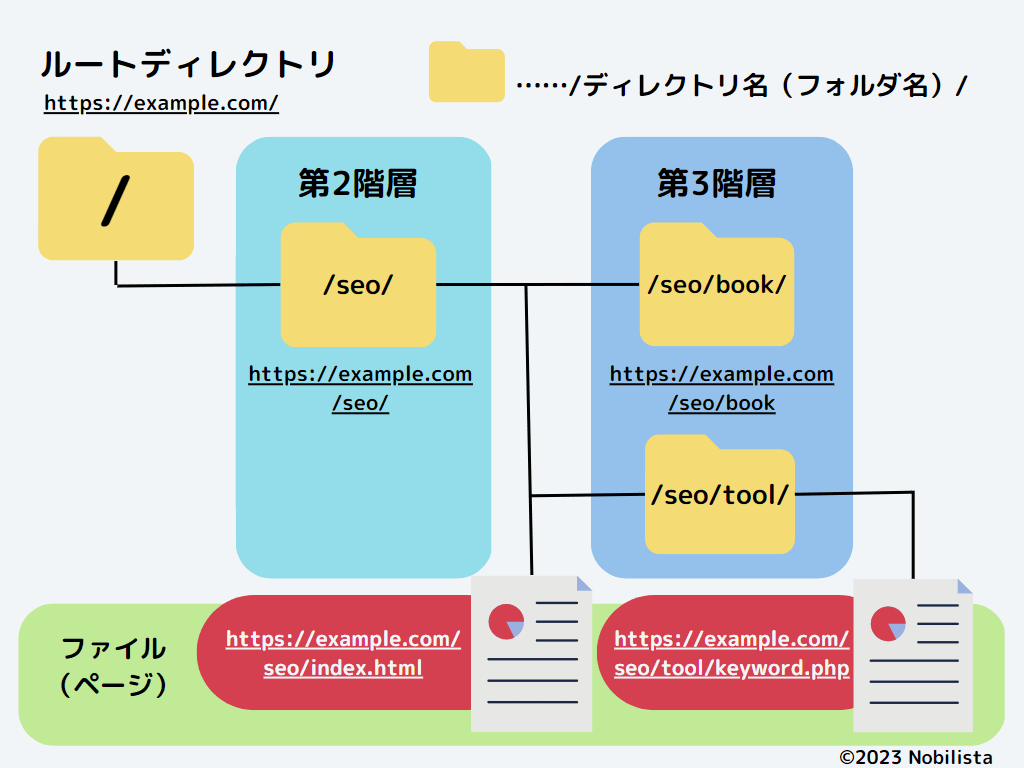
大きなフォルダの中に、Webサイトを構成するためのデータが保存されています。
この最上位のフォルダを「ルートディレクトリ」と呼びます。最も外側にあるフォルダであり、すべてのデータの出発点となる場所です。ちなみに「ディレクトリ」とは、フォルダの別名です。
フォルダの中にはさらにフォルダを作成できます。Webサイトの仕組みも同じで、たとえば「/seo/」というディレクトリの中に「/seo/book/」というディレクトリを入れることができます。
このように、ディレクトリの中に存在するディレクトリを「サブディレクトリ」と呼びます。イラストで表すと「/seo/」や「/seo/book/」がサブディレクトリにあたります。
Webサイトの構造を理解するには、平面的に考えるよりも立体的にイメージするとわかりやすいです。ディレクトリを箱のような空間として想像すると、階層構造が直感的にイメージできます。
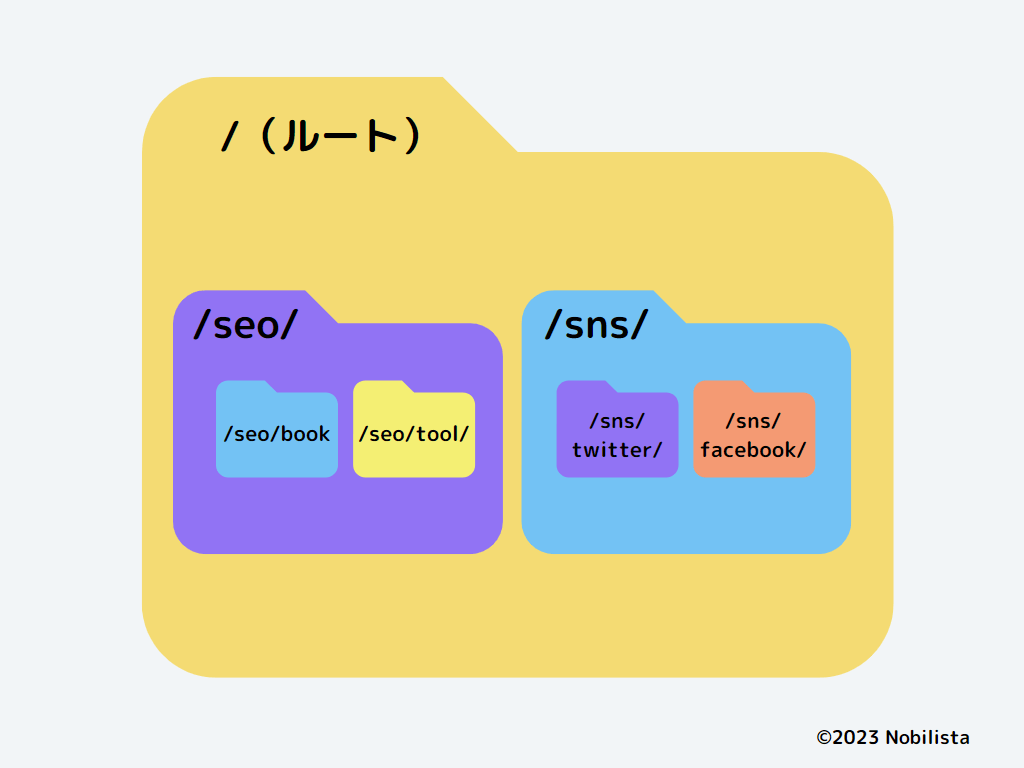
上記のように、Webサイトは入れ子式の構造をしています。
すると、なぜ第2階層、第3階層といわれるのか、わかりやすいのではないでしょうか。
ディレクトリの奥に入っていく、つまり階層が深くなっていくイメージから、たとえば「/seo/book/」は「/seo/」の下層や配下といった表現をします。
このWebサイトが立体的な構造をしていることを理解しておくと、robots.txtの記述について理解しやすいはずです。
また、関係するURLの要素についても見ておきましょう。

Webサイトのページをはじめ画像などのファイルに、実はURLがついています。
robots.txtでは、上記の完全修飾ドメイン(FQDN)とサブディレクトリ、パラメータのある場所を覚えてください。
それぞれの要素のくわしい説明やどんなURLかは、以下の記事をご覧ください。
SEOとURLの関係性とは?SEOに効果的なURLの設定方法を解説
どんな時にrobots.txtを利用する?

robots.txtを意識したいWebサイトとは、一言でいうとページ数が多く「クロールの節約」が必要な大規模サイト。
俗にいう、クロールバジェット(クロールの割り当て)の問題です。
クローラーは頼まずともWebサイトを回遊してくれますが、無限にクロールしてくれるわけではありません。
なぜなら、クロールという行為は、多少なりともサーバーに負荷をかけるからです。
そのため、あまりにもページ数が多い大規模サイト(またはリダイレクトを大量にしているサイト)ではクロールが制限され、その結果インデックス(さらには検索結果への表示)へ影響を与えることがあります。
これが、クロールバジェットの問題点といえるでしょう。
そこで、robots.txtを使い、クロールが不要なページへのクロールを制限。
本来クロールして欲しいページへの割り当て量を増やすというのが、robots.txtの主な使い方です。
ただし、Googleとしては、よほど大規模なWebサイトでない限り、心配する必要はないとのこと。
よほどの大規模サイトとは、ページが数千を超える規模と考えましょう。
もしあなたのWebサイトが該当する場合。
どのようなページのクロールを、robots.txtで制限したらよいか。
いくつか例をご紹介します。
- 会員向けページやログイン画面(管理画面)といった「認証ページ」
- SEOツールなどの「独自クローラー」
会員向けページやログイン画面(管理画面)
パスワードが設定されている会員向けページやマイページへのログイン画面、その配下のすべてのページは、いずれもクロールが不要なページです。
こういったページは、robots.txtでクロールを制限しても問題ありません。
たとえばWordPressの場合、初期設定で「wp-admin」というディレクトリにrobots.txtを設定しています。
この「wp-admin」は何かというと、管理画面に関するファイルが入っている場所です。
SEOツールなどの「独自クローラー」
SEOツールの独自クローラーをはじくために、robots.txtを使うといった例もあります。
クローラーとは、Googleの検索エンジンに限ったものではありません。
ほかの検索エンジン(「bing」など)のクローラーや、特定のSEOツールがデータ取得のために走らせている独自クローラーもいます。
たとえば「Ahrefs」や「Semrush」といった、SEOツールを思い浮かべてください。
他サイトのURLを入力すると、被リンクの数やキーワードの順位など、すべてわかってしまいます。
これは、独自クローラーがWebサイトをクロールし、情報を集めているからです。
クロールバジェットのためとは少し違いますが、他サイトに情報を渡さないため、robots.txtを設定するという使い方もあるということを覚えておきましょう。
SEOツールおすすめ16選!無料・有料、Google公式ツールまで価格や機能を比較
robots.txtを反映する流れ

robots.txtを使ってクローラーを制御するまでの、一連の流れをご紹介します。
- robots.txtを反映する流れ
- robots.txtのファイルを作成
- Webサイトにファイルをアップロードする
- robots.txtファイルのテストを行う
①robots.txtのファイルを作成
まずは、robots.txtのファイルを作ります。
ファイルは、テキストエディタを使って、作成しましょう。
代表的なテキストエディタは「Visual Studio Code」「Atom」などです。
ただ、日常的にプログラミングやコーディングを行うのでなければ、テキストエディタがないという方も多いと思います。
そのような方は、PCにある「メモ帳」を使いましょう。
メモ帳も、テキストエディタの一つなので問題ありません。
robots.txtファイルの中には、以下のような内容の記述を行います。
(くわしい書き方は後ほどご紹介するので、軽く見るだけで大丈夫です。)
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
Sitemap: http://www.example.com/sitemap.xml
robots.txtファイルを保存する際、ファイル名はかならず「robots.txt」にしましょう。
「s」を忘れないように。
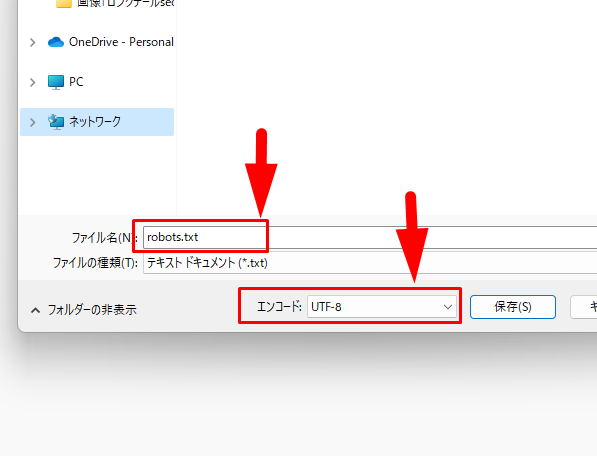
エンコードの部分が「UTF-8」であることも、一緒に確認しましょう。
似ているもので「UTF-8(BOM付き)」というものを選ばないように注意してください。
ちなみに、保存したファイルをデスクトップ画面で見ると「.txt」部分が消えていることがあります。
これは、拡張子(.txt)が省略されているだけなので、気にしなくて大丈夫です。

②Webサイトにファイルをアップロードする
robots.txtのファイルが作成できたら、ファイルをWebサイトへアップロードします。
ファイルのアップロードは「FTPソフト」を使いましょう。
ファイルはかならず、ルートディレクトリ(ルートフォルダ)にアップロードしてください。
基本的に「/」や「root」といった名前がついているはずです。
使っているサーバー(ホスティングサービス)によっては、アクセス権限が必要な場合があります。
事前に確認するようにしましょう。
たとえば「https://example.com/」のrobots.txtファイルをURLで見ると、以下のようになります。
https://example.com/robots.txt
そして、ホスト(サブドメイン)を使用している場合。
ホスト名やサブドメイン名のついた、完全修飾ドメイン(FQDN)になっているかしっかり確認しましょう。
https://blog.example.com/robots.txt
https://www.example.com/robots.txt
上記のrobots.txtは、たとえば「https://example.com/robots.txt」には適用されません。
そして、ルートディレクトリ以外のサブディレクトリに入れているrobots.txtファイルは、無効となります。
つまり、以下のようなrobots.txtファイルは無効です。
https://example.com/seo/robots.txt
どこのディレクトリにアップロードしたか、どのドメインにアップロードしているかは間違えないようにしましょう。
サブドメイン・サブディレクトリとは?どっちがSEOに有利?違いやメリット・デメリット、使い分けのやり方を解説
③robots.txtファイルのテストを行う(テスターを利用)
robots.txtをアップロードして終わりではいけません。
かならず、記述にエラーがないか、テストを行ってください。
まず、アップロードができているかどうかを確認しましょう。
シークレットブラウザ(WindowsやChromeは「Ctrl+Shift+n」、Macは「⌘+shift+n」)で、robots.txtファイルのURLをアドレスバーに入力します。
先ほどの例であれば、以下のURLです。
https://example.com/robots.txt
https://blog.example.com/robots.txt
https://www.example.com/robots.txt
アップロードが出来ていたら、記述内容と同じものが表示されます。

アップロードが確認できたら、記述に間違いがないかのテストを行いましょう。
方法は2つあります。
- Googleサーチコンソールの「robots.txtテスター」を使う
- 「robots.txt ライブラリ」を利用
おすすめは「1」のrobots.txtテスターを使った方法です。
(「2」はWeb知識がある人向け。ただし、ローカル環境でテストしたい場合はこちら。)
具体的なエラーテストのやり方は、のちほど解説します。
(補足)アップロードが不要なケースとWordPressのrobots.txt
WixやBloggerといった、一部のレンタルサーバー(ホスティングサービス)では、robots.txtファイルを作る必要がなかったり、アップロードができない場合があります。
たとえばBloggerでは、設定画面での操作が基本です。
ファイルをアップロードする必要はありません。
WordPressの場合は、すでにお話したとおり、初期設定としてrobots.txtがすでにあります。
ただ、基本的にrobots.txtファイルを設定できる機能がないので、以下のいずれかの方法を選びましょう。
- プラグインを使って編集、追記
- 既存の記述に追記した形で新規robots.txtファイル作成→FTPソフトでアップロード
簡単なのは、プラグインの利用です。
ただ、プラグインを増やしたくないという方は、FTPソフトでのrobots.txtファイルアップロードをおすすめします。
WordPressでrobots.txtファイルを編集する場合のプラグイン(総合型)は次のとおりです。
- All in One SEO
- Rank Math SEO
- Yoast SEO
以下は、robots.txtファイル編集のためだけの特化型プラグインです。
- WP Robots Txt
- Virtual Robots.txt
プラグイン・FTPソフト、いずれの方法でも、書き方はこのあと紹介する記述方法を参考にしましょう。
注意点として、WordPressの既存の記述は消さずに、追記する形で編集することです。
たとえば、以下のrobots.txtファイルがあったとします。
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xml
「Disallow: /seo/」という記述を追加するなら、以下のように追記してください。
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Disallow: /seo/ ←追加した記述
Sitemap: http://www.example.com/sitemap.xml
いずれにせよ、まずは自身のWebサイトのレンタルサーバーでは、robots.txtの使用についてどのようなアナウンスがされているか、事前に調べることをおすすめします。
WordPressのSEO対策設定のやり方とは?初心者向けにプラグインや投稿設定を方法を解説
robots.txtの記述例と書き方

robots.txtファイルの中身はいわば、クローラーの言語で書かれた指示書です。
robots.txtの書き方と一緒に、ファイルのなかには何が書かれているのか、それぞれの記述の意味も併せて理解していきましょう。
まず、robots.txtファイルの記述の基本形は以下です。
User-agent:
Disallow:
Allow:
それぞれの要素を見てみましょう。
| User-agent: (記述例) User-agent: * | 指示の対象(制御するクローラーの名前) ※先頭にかならず入る。 |
| Disallow: (記述例) Disallow: /wp/wp-admin/ | クロールを許可しない場所 ※Disallow: かAllow: のいずれかがかならず入る。 |
| Allow: (記述例) Allow: /wp/wp-admin/admin-ajax.php | (特例で)クロールを許可する場所 ※Disallow: かAllow: のいずれかがかならず入る。 |
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
上記の記述を、言葉に直してみましょう。
以下のような意味になります。
| User-agent: * | 以下は、すべてのクローラーに対しての指示です。 |
| Disallow: /wp/wp-admin/ | 「https://example.com/wp/wp-admin/」の配下にある、すべてのディレクトリやファイルへのクロールを許可しません。 |
| Allow: /wp/wp-admin/admin-ajax.php | ただし、例外として「Allow: /wp/wp-admin/admin-ajax.php」というファイルへは、クロールされるよう許可を出します。 |
では、一つひとつの要素の具体的な記述例を解説します。
また、ルールを応用した便利な記述例も紹介しているので、ぜひ参考にしてみてください。
User-agent:
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xml
「User-agent:」は、ルールを適用させる対象(クローラー)を指定する部分。
クローラーにも種類があり、役割ごとに名前(ユーザー エージェント トークン)がついています。
クローラーを限定したい場合は、User-agent:の部分に名前を記載しましょう。
| クローラーの役割 | ユーザー エージェント トークン |
| パソコン用Googlebot | Googlebot |
| スマートフォン用Googlebot | Googlebot |
| 画像用 Googlebot | Googlebot-Image(Googlebot) |
| 動画用 Googlebot | Googlebot-Video(Googlebot) |
| AdSense | Mediapartners-Google |
その他のGoogleクローラーについては「Google クローラーの概要(ユーザー エージェント)」をご覧ください。
「User-agent:」の記述例_一部のクローラーを指定
【指示】
全ページ、Google検索エンジン(PC・スマホ用)と画像用クローラーのクロールを許可しない。
User-agent: Googlebot
User-agent: Googlebot-Image
Disallow: /
「User-agent:」の記述例_すべてのクローラーを対象
【指示】
全ページ、すべてのクローラーからのクロールを許可しない。
User-agent: *
Disallow: /
基本的に、すべてのクローラーを対象とする「*(アスタリスク)」がよく使われます。
Disallow:
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xml
「Disallow:」では、クロールを「許可しない(disallow)」ページやファイルを指示する部分。
User-agent:のあとには、かならずDisallow:か後述のAllow:のいずれかが入ります。
指示の先頭は「/」から始まるようにしましょう。
「Disallow:」の記述例_すべてのURL
【指示】
すべてのURL(全ページ)に対して全クローラーのクロールを許可しない。
User-agent: *
Disallow: /
Webサイトの全ページ(ファイル)を指定する場合は「/」を記載しましょう。
「Disallow:」の記述例_ディレクトリを指定
【指示】
「/seo/」というディレクトリと、その配下のファイルすべてに対して、全クロールを許可しない。
User-agent: *
Disallow: /seo/
クロールを許可しない場所がディレクトリの場合。
指示の最後には「/」がつきます。
たとえば上記の場合「/seo/tool.html」や「seo/technical/book.html」といった「/seo/」ディレクトリの下層にあるディレクトリやファイルのすべてが、クロールされなくなります。
「Disallow:」の記述例_サブディレクトリを指定
【指示】
「/marketing/study/book/」というディレクトリ配下すべてに対し、全クロールを許可しない。
User-agent: *
Disallow: /marketing/study/book/
上記の場合「/book/」配下の「/book/seo.html」といったページやファイルにもrobots.txtは適用されます。
ただ、たとえば「/marketing/study/tool/」のような、「/book/」より一つ上の「/study/」内の別ディレクトリには反映されません。
ちなみに、同じクローラーに対して、複数の指示がある場合は続けて記述できます。
User-agent: *
Disallow: /marketing/study/book/
User-agent: *
Disallow: /marketing/study/video/
たとえば、上記のような記述は、以下のように自動で統合されます。
User-agent: *
Disallow: /marketing/study/book/
Disallow: /marketing/study/video/
「Disallow:」の記述例_ページ名を指定
【指示】
「https://example.com/seo.html」と「/marketing/study/book.html」というページのみ、全クローラーを許可しない。
User-agent: *
Disallow: /seo.html
Disallow: /marketing/study/book.html
特定のページ(ファイル)のクロールを制御したい場合。
「.html」や「.php」といった拡張子までつけた、完全なファイル名を記載しましょう。
「Disallow:」の記述例_ファイル名を指定
【指示】
「https://example.com/images/logo.jpg」という画像ファイルへ、画像用クローラーのクロールを許可しない。
User-agent:Googlebot-Image
Disallow: /images/logo.jpg
ちなみに、画像のアドレス名は以下の方法で取得できます。
- 画像の上で右クリック
- 「画像アドレスをコピー」を選択
- メモ帳などにペースト(URLが表示)
「Disallow:」の記述例_特定の末尾で終わるもURLのみ
【指示】
末尾に「.php」がつくすべてのファイルに対して、全クローラーのクロールを許可しない。
User-agent: *
Disallow: /*.php$
「$」はURLの末尾を表します。
「$」がついた以降(下層)のディレクトリやファイル、パラメータには、Disallow:の影響を与えません。
つまり「seo.php?sort=new」や「seo.php.file.html」といったURLはクロールされます。
「Disallow:」の記述例_特定の文字を含むURLのみ
【指示】
「.php」を含むすべてファイルに対して、全クローラーのクロールを許可しない。
User-agent: *
Disallow:/*.php
上記の記述で、robots.txtの影響を受けるURLと、そうでないURLは以下です。
- 影響を受けるURL例
https://example.com/index.php
https://example.com/book.php
https://example.com/book.php/
https://example.com/seo/book.php
https://example.com/seo/book.php?sort=new
https://example.com/seo/book.php.file.html - 影響を受けないURL例
https://example.com/
https://example.com/book.PHP
ちなみに、User-agent:以外の記述は、大文字・小文字を判別します。
間違えないようにしましょう。
「Disallow:」の記述例_特定の順番で特定の文字を含むURLのみ
【指示】
「/seo」と「.php」を含み、この順番で並ぶURLに対して、全クローラーのクロールを許可しない。
User-agent: *
Disallow:/seo*.php
上記の記述で、robots.txtの影響を受けるURLと、そうでないURLは以下です。
- 影響を受けるURL例
https://example.com/seo.php
https://example.com/seo-study/seo-book.php?sort=new - 影響を受けないURL例
https://example.com/SEO.PHP
Allow:
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xml
「Allow:」は、Disallow:とは逆にクロールを「許可する(allow)」場所を指示する部分。
Disallow:で指示しているなかで、例外的にクロールをしたい場合に使います。
Disallow:と同様、記述の先頭はかならず「/」から始めましょう。
ちなみに、Disallow:よりも効果が優先されます。
「Allow:」の記述例_特定のディレクトリのみクロールを許可
【指示】
全クローラーに対して「/seo/」ディレクトリのみクロールを許可し、それ以外のページはすべてクロールを許可しない。
User-agent: *
Disallow: /
Allow: /seo/
「Allow:」の記述例_特定のクローラーのみクロールを許可
【指示】
動画用クローラー「Googlebot-Video」を除き、ほか全クローラーのクロールを許可しない。
User-agent: *
Disallow: /
User-agent: Googlebot-Video
Allow: /
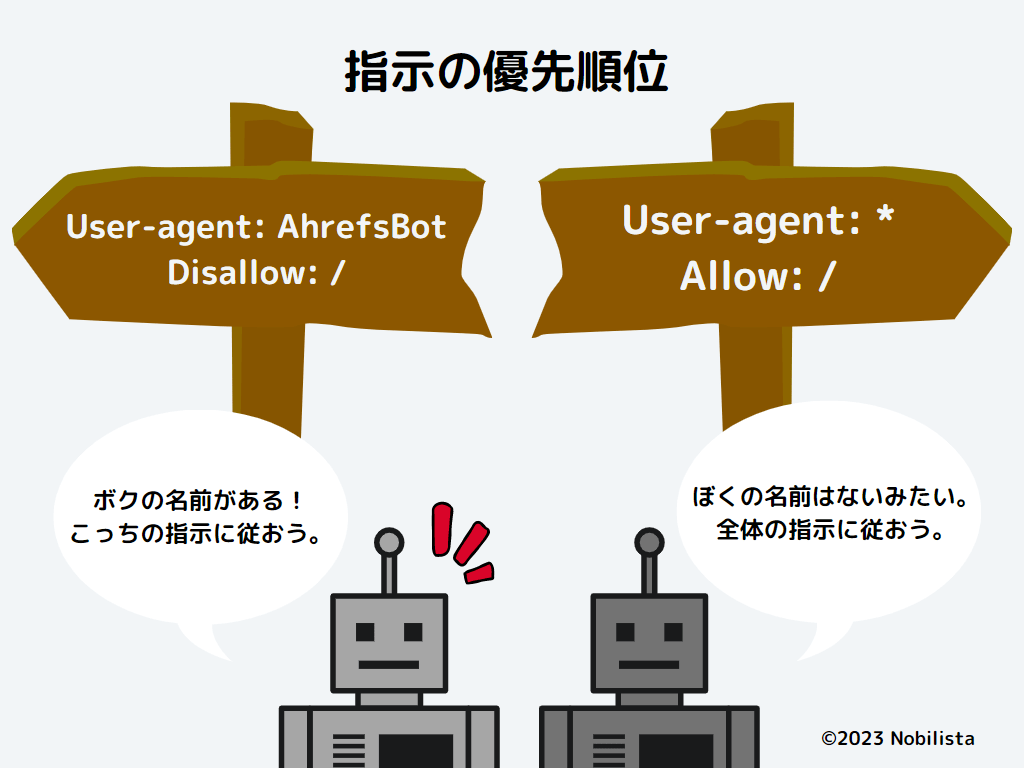
「Allow:」の記述例_
【指示】
「AhrefsBot」と「SemrushBot」のクロールを全ページ許可しない。
それ以外のクローラーは、全ページクロールを許可する。
User-agent: AhrefsBot
User-agent: SemrushBot
Disallow: /
User-agent: *
Allow: /
robots.txtの記述は、クローラーが限定(指名)されている指示ほど優先されます。
そのため、上記の場合「Ahrefs」と「Semrush」のクローラーは、全クローラーを意味する「*」の指示(Allow: /)よりも、名指しの指示(Disallow: /)を優先する点に注意しましょう。
Sitemap:
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xml
サイトマップを記述する部分です。
必須項目ではありませんが、記載することで検索エンジンが見るべき箇所が絞られ、robots.txtの反映が早まる可能性があります。
サイトマップは、すべての記述の一番最後に記載しましょう。
ほかの記述の間に書くと、場所によっては気づかないうちに、想定しない指示をしてしまうこともあります。
サイトマップが複数ある場合は、あるだけ記載してください。
Sitemap: https://example.com/sitemap.xml
Sitemap: http://example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://blog.example.com/sitemap.xml
Sitemap: https://ja.example.org/テスト-サイトマップ.xml
上記のとおり、完全装飾URL(FQDN)で記述します。
また「http://」と「https://」や「www」のありなしも、明確に分けて記載しましょう。
XMLサイトマップ(sitemap.xml)とは?作り方やSEO効果、Googleへの送信方法を解説
robots.txtのエラーテストのやり方

robots.txtのファイル作成、アップロード後はかならずエラーテストを行います。
今回は「robots.txt テスター」を使うやり方を紹介しましょう。
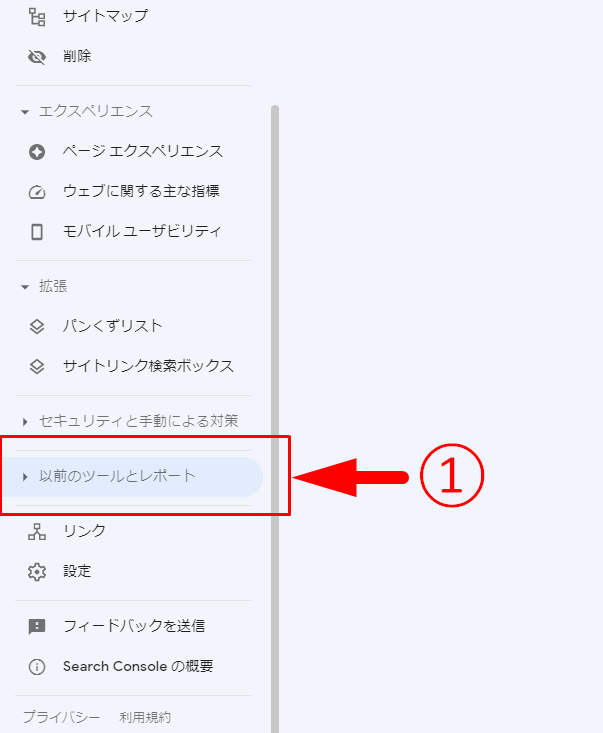
Googleサーチコンソールの「以前のツールとレポート」を選択してください。
「robots.txt テスター」をクリック。
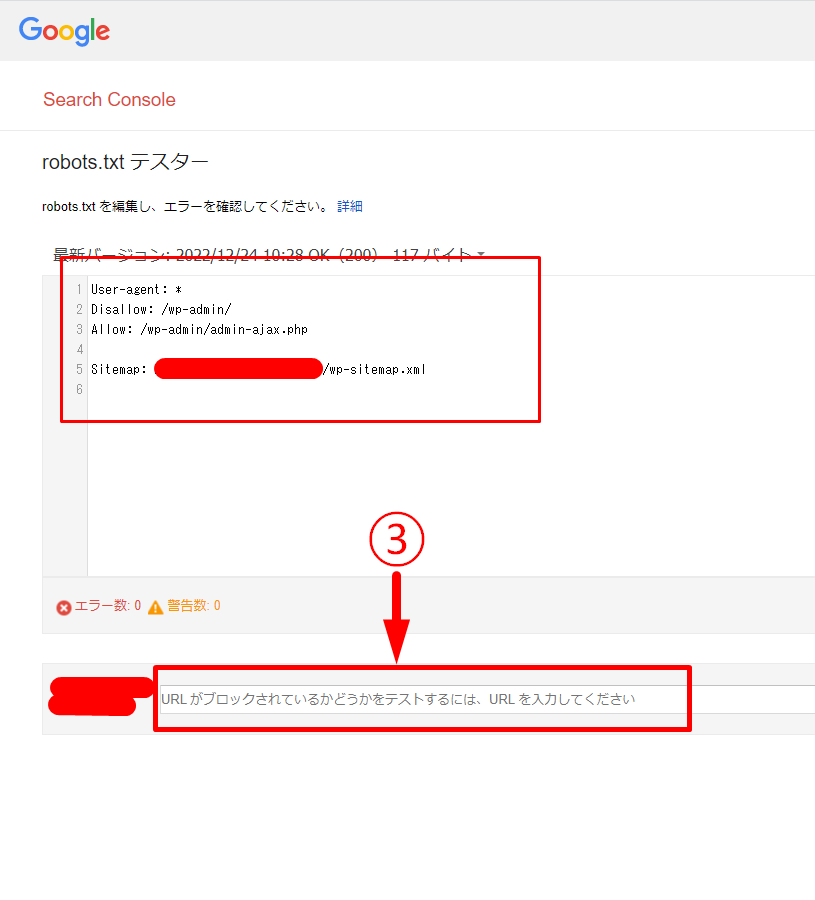
記述した内容が表示されていることを確認しましょう。
ファイルが認識されていない場合は「見つかりません」と表示が出ます。
この時点で記述が間違っていたら「エラー数」に表示が出ます。
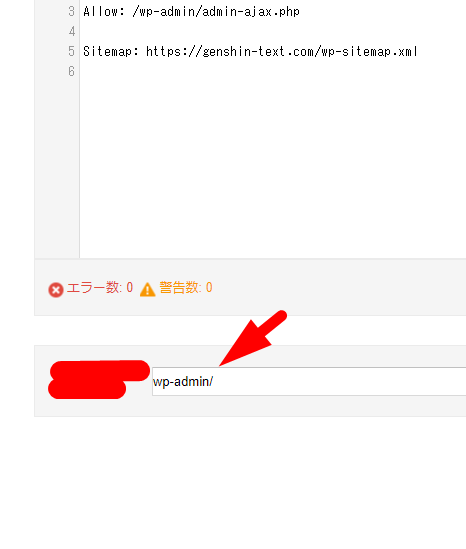
Disallow:またはAllow:で記載した、パス名を入力。
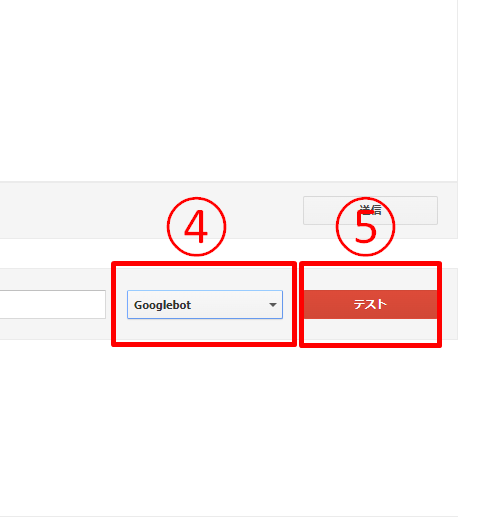
User-agent:で記載したクローラーを選択します。
「テスト」をクリック。
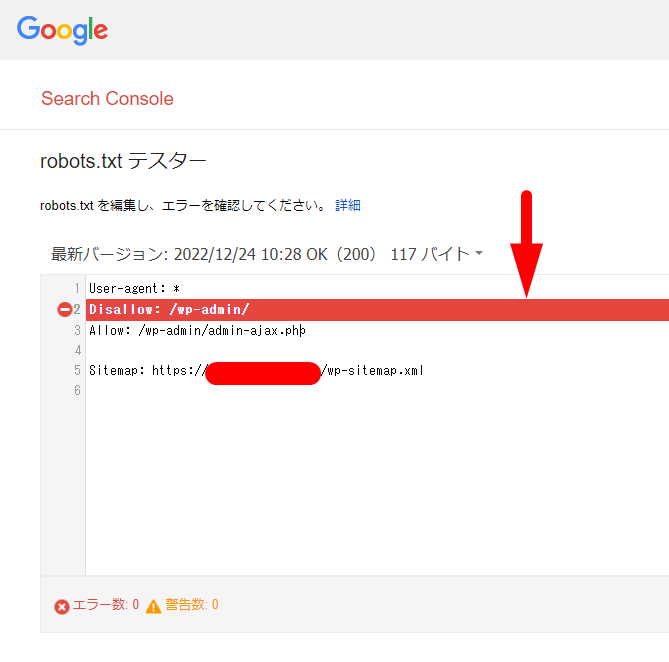
赤いラインと通行止めのようなマークが出ていたら、robots.txtがしっかり機能している証拠です。
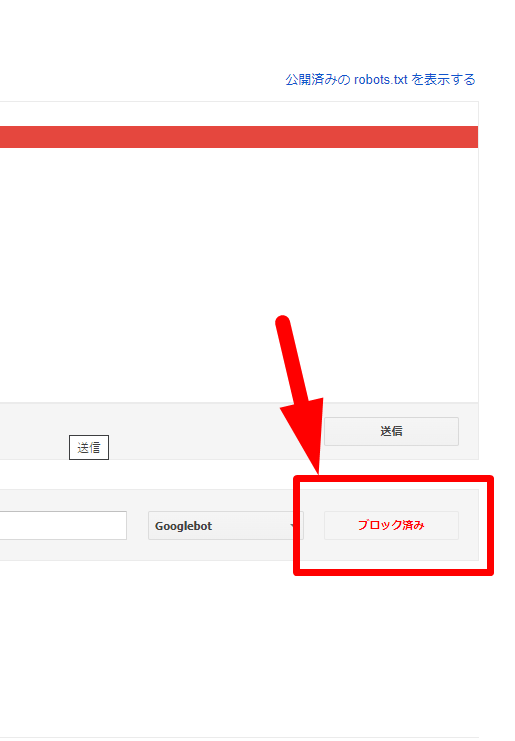
さらに、先ほど「テスト」だったボタン部分も確認します。
「ブロック済み」となっていたら問題ありません。
robots.txt利用時の注意点

robots.txtを利用する前に知っておきたい、注意点にも触れておきましょう。
robots.txtは場合によって、SEOに多大な影響を与える可能性があります。
利用の際には、細心の注意を払ってください。
- ユーザーの閲覧を制限するためものではない
- クローラーによってはrobots.txtを無視するものもいる
- robots.txtの反映は時間がかかる
- robots.txtの記述内容は誰でも見られる
- ルール外の記述は無効化され、記述が繰り上げられる
ユーザーの閲覧を制限するためものではない
noindexのところでも軽く触れましたが、robots.txtはクローラーを制御するためのもの。
そのため、ユーザーの閲覧を制御する効果はありません。
たとえば、アドレスバーにURLを直打ちしたら、もちろんそのページは見ることができます。
インデックスも残るため、検索結果にも表示されるでしょう。
ユーザーの閲覧も制限したい場合は、認証によるアクセス制限やnoindexタグの利用をおすすめします。
noindexタグとは?設定方法やSEOへの影響、実装ページの確認方法を解説
クローラーによってはrobots.txtを無視するものもいる
robots.txtは完璧ではありません。
robots.txtの指示を無視するクローラーもいます。
その際は別の方法(.htaccessなど)を試しましょう。
.htaccessとは?書き方や設定方法、読み方、ファイル作成方法を解説
robots.txtの反映は時間がかかる
robots.txtの反映は、その日や翌日といった明確な目安がありません。
1週間以上かかる可能性も考え、反映されなくてもある程度は様子を見る様にしましょう。
robots.txtの記述内容は誰でも見られる
robots.txtファイルはシークレットブラウザで誰でもみることができます。
たとえばrobots.txtの記述内容に、コメントアウトで見られたくない情報を記載しないよう注意しましょう。
ルール外の記述は無効化され、記述が繰り上げられる
robots.txtは、ルールに則らない記述(User-agent:とDisallow、Allow以外を使うこと)をすべて無視します。
たとえば、以下の記述をご覧ください。
user-agent: googlebot
sitemap: https://example.com/sitemap.xml
user-agent: Googlebot-Image
disallow: /
robots.txtは、上記の記述を以下のように変換して適用します。
user-agent: googlebot
user-agent: Googlebot-Image
disallow: /
上記がいかに深刻な状態か、わかるでしょうか。
画像用クローラーの「Googlebot-Image」だけ外すつもりが「googlebot」つまり普通の検索エンジン用クローラーも全ページはじいてしまっています。
また、スペルミスにも注意が必要です。
user-agent: googlebot
alow: /
user-agent: Googlebot-Image
disallow: /
上記は「allow」が「alow」とスペルミスしている記述です。
robots.txtは、以下のように解釈するでしょう。
user-agent: googlebot
user-agent: Googlebot-Image
disallow: /
こちらも画像用クローラーだけ外すつもりが、検索エンジン用クローラーに対してもdisallowが適用されています。
気づかぬうちに意図しないページに対してrobots.txtを反映させていた。
このようなことがないよう、記述にはよく注意してください。
最初にもお話したとおり、基本的に数千ページ超えの大規模サイトでなければ、クロールバジェットの問題を気にする必要はありません。
むしろ、robots.txtは扱い方を間違えれば、SEOに影響が出ることもあります。
関連する記事一覧